SIMULIA电磁学仿真中的机器学习
SIMULIA 很高兴与工程领导者和学术界合作,因为他们利用仿真功能来帮助塑造行业的未来。今天,我们很自豪地邀请到来自Technical University of Graz的 Jan Carsten Hansen,他是 2023 年 SIMULIA 冠军,他将如何看待机器学习可以为电磁仿真带来的可能性。
您能告诉我们机器学习以及它如何使电磁学受益吗?
电子系统及其电磁耦合路径非常复杂。存在一般规则并写在教科书中。然而,单独的电子设计太多了,无法根据规则预测它们的电磁相互作用。通常,在任何大公司内部,都有经验丰富的 EMC 工程师,他们根据多年的经验,可以最好地判断系统可能出现的 EMC 问题的风险以及如何缓解这些问题。他们之所以能做到这一点,是因为他们是专家,在他们的生活中见过很多产品,在各种情况和运行状态下。

扬·卡斯滕·汉森
机器学习是关于体验的。我们根据可用数据训练模型。一旦模型足够准确,我们就会使用它来研究模型训练的有趣案例。该模型的主要优点是它可以处理相当多的参数,这些参数可能会发生变化,并且计算速度非常快。最后,该模型模拟了经验丰富的 EMC 工程师所做的工作:根据一些观察,我们对类似情况得出结论。当然,经验丰富的 EMC 工程师的大脑比任何 ML 模型都要聪明得多,可以推断出更多的东西。但是 ML 模型学习得非常快,它可以一天 24 小时学习。如今,我们面临着如此多的技术新奇事物。我相信 ML 模型可以帮助 EMC 工程师快速获取知识,这比基于个人试错调查的速度要快得多。
您能否概述一下在格拉茨理工大学的工作中将 AI 与 EMC 模拟集成的主要动机?
我有两个动机,它们处于不同的成熟状态。第一个是多目标优化。在产品设计中,没有我喜欢寻找的唯一最佳选择。总是需要权衡取舍,即给定预算所需的质量。因此,我花的钱越多,我的产品的质量和使用寿命就越高。如果钱少了,我就无法设计出同样质量的产品。但我一直喜欢的是我投资的钱的最佳品质。现在,在产品设计中,有很多这样的权衡;成本是其中之一,EMC 限制、性能和效率、热设计等。通常,如果你改进一个,它会破坏其他一些。为了评估这些权衡,需要研究许多样本。ML 模型为生成这些样本提供了绝佳的机会。
第二个主题是 EMC 模型的复杂性。特别是,在高频下,例如,集总元件模型不再足够精确,我需要解决电磁问题;我需要收集许多参数来组装我的模型。材料参数、尺寸、设备型号(例如用于半导体)、有关驱动任何信号的软件的信息等。我可以这样做,但这需要时间。人们通常做的是猜测大部分缺失的信息。因此,在 3D EM 模型中,存在很多参数不确定性。我知道参数的范围,但我不知道它们的准确值。为了将不确定的模型变成准确的模型,我们需要校准这些模型。大多数情况下,至少有一些测量值可用于研究对象对某些激发的响应。我喜欢使用 ML 方法来使用这些测量来校准不确定的参数。这是一项统计推断任务,也就是说,我们估计最有可能产生正确测量结果的参数集。由于统计数据还需要许多模型评估,因此 ML 模型是找到此参数集的唯一可能性。
什么是代理模型,为什么它对 EMC 分析有用?
什么是代理模型有几种定义。对我来说,代理模型是一种模仿被测系统的物理反应的行为模型。此模型不显示有关系统的任何物理信息,但它是根据物理模型或测量或两者构建而成的。此外,我所说的代理人的评估速度非常快,这使它们如此强大。基本上,它是一个基于许多参数的非参数回归模型。有很多方法。你经常发现神经网络,因为它们很容易实现,但还有更多,比如高斯过程、多项式混沌展开等。
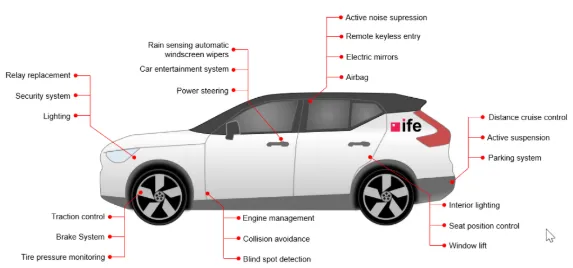
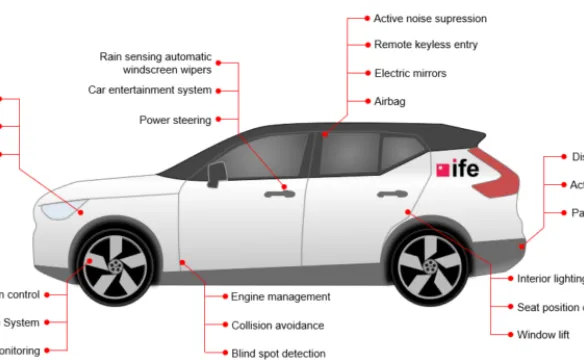
图 1:现代车辆包含各种各样的电子元件,这些电子元件构成了一个复杂的电子系统。
如上所述,EMC 非常重视案例研究和积累经验。此外,EMC 是次要产品属性。没有人会因为产品在 EM 合规性方面的出色表现而购买该产品。因此,EMC 设计面临着权衡取舍的想法。给我一个在许多方面都尽可能酷并且通过 EMC 要求的产品。权衡需要许多模型评估,这就是我需要代理项的原因。
使用 AI 进行 EMC 仿真的典型工作流程是什么?如何将 CST 仿真结果与 AI 模型联系起来?
首先,您需要一个初始采样集来训练您的模型。生成此信息后,您需要有关系统的物理信息。您需要从CST 的。Python 接口在这里非常有用。遗憾的是,有关此接口的可用信息比应有的要少。掌握后,您可以在训练数据集上多次评估您的模型并编译代理模型。您也可以分几个步骤执行此操作;例如,您从一个小型训练数据集开始,编译一个模型,然后针对更多可用数据测试模型。如果模型还不准确,则会生成更多训练数据,尤其是在模型不佳的领域,然后继续训练。这称为自适应学习。对于确定性模型需要较长计算时间的情况,这是一种明智的策略。说 AI 其实很夸张。AI 需要数千或数百万个训练数据。我们只处理回归,需要大约 100 个训练数据,这是因为我们使用的是计算量很大的模型,这是我们能承受的最大数量。
与全波模型相比,您如何确保这些 AI 生成的代理模型保持高水平的准确性?
这很简单。全波模型(或任何其他物理模型)始终可用。我可以针对全波模型测试我的代理项,在我的训练过程中,我无论如何都会这样做。此外,当我使用代理在某个优化任务中计算出最佳参数配置时,我总是在原始物理模型中应用此参数集来检查代理是否预测良好。
AI 中最重要的技术进步是什么,使其能够在 EMC 仿真中得到应用?
AI 和 ML 模型最令人兴奋的特点是它们打破了维度的诅咒。在高维空间中,数据点往往会变得稀疏和分散。对给定设计空间进行完全采样所需的数据点数量随着维度数量的增加呈指数增长:要对每个维度有 3 个样本的 3D 空间进行采样(三个样本很少:它类似于 min/max/ 和介于两者之间的一个值),我需要 3个 3=27 个样本。如果是 8 维的,则为 38= 6561,而 15 维则超过 1400 万个样本。

图 2:电动动力总成是电动汽车的心脏,也是其主要排放源。(图片由宝马集团斯太尔工厂提供)
ML 解决了这个问题。存在适用于 15 维甚至 18 维设计空间的复杂采样策略。根据我们迄今为止调查的所有案例,我们从未需要超过 1000 个训练样本。这太神奇了。这适用于许多不同的 EMC 问题,无论是 EMI 滤波器、电源转换器还是屏蔽线的辐射发射模型。
在 EMC 模拟中使用 AI 在哪些情况下最有益?
我们看到了 AI 在早期设计中电子系统的多目标优化方面的直接好处。在早期设计中,仍有许多参数未知。使用多目标优化,我们可以快速看到各种“最佳”解决方案的最佳设计基准,无论我们关注的是哪种最优性。如果已经有硬件样本可用,我们可以检查这种实现与最佳基准相差多远。当然,AI 没有解决的是如何将这个最佳参数集转换为真实的 3D 设计。但是,由于可以生成许多最优设计,因此可以快速确定一个可行的设计,然后证明该设计接近最优。
与全波 3D 相比,代理模型快多少?它何时变得比 3D 更高效(包括初始计算和训练时间)?
时间收益是巨大的。一般来说,有四个因素。评估物理模型的时间很重要(如果时间太短,例如在快速交流电路仿真中,则不需要 ML)。我需要的训练数据数量也很重要。第三个,构建代理的时间通常与前两个相比可以忽略不计。评估它的时间非常快。我们有在 300 微秒内运行的模型,有些需要几毫秒。需要的训练数据越多,ML 模型的评估速度就越慢。平均而言,我们每天可以运行大约 10 个 Mio 样品。对于确定性模型来说完全不可能。从本质上讲,我将 ML 模型视为解决方案的容器,而不是模型。
展望未来,您的工作下一步或未来发展是什么?
首先,我想看看我们提出的最佳设计。如果我们能够证明 ML 可以快速找到性能优于现有设计的设计,那么我们就有很好的证明了 ML 的好处。我们正在研究电力驱动,我们的工业合作伙伴肯定会从我们的估计中获得真实的硬件样本。我非常期待看到这些样本并评估它们的表现。
其次,我对模型校准非常感兴趣。我们已经对最初的简单样品进行了研究,结果非常有希望。接下来,我们想将此技术应用于复杂的硬件示例。我真的很兴奋,看看我们是否能以比今天看到的精度高得多的方式生产出这些模型的高频 EMC 模型。
最后,我对训练具有物理约束的 AI 模型也非常感兴趣。现在,训练过程纯粹是统计的;我们的 AI 模型不是很复杂,也不知道任何物理关系。考虑到我们已经求解麦克斯韦方程组 150 多年了,这是相当轻率的。现在我们把这些信息扔到海里,一切都是随机的。我们最近构建了一个 ML 模型,该模型理解 Kirchhoff 电流定律,这是电路的基本定律。这是一种随机方法,但我们可以教它,无论它预测什么,所有节点的电流之和总是为零。这是在为 ML 模型配备每个人类工程师显然都拥有的一些确定性知识方面向前迈出的一大步。我希望通过在训练中加入物理定律,我们可以显著减少训练数据的数量。这对于训练时间较长的模型非常重要。这项研究很有趣,也非常有趣,所以即使我们还有很长的路要走,这不仅仅是一次伟大的学术练习。